
Web interface: User manual
To search and download the corpus, click on the tab ‘Search/Download’, where you can do a ‘simple search’ or an ‘advanced search’. The web interface has been designed so as to be as simple and intuitive as possible. Next to each search element, you will see a question mark symbol like this: Click on it to get help about how to use each element. Additionally, the search interface is divided into coloured sections to help you visualize the different sections.
SIMPLE SEARCH: Use this to look for a word (or a combination of words in the corpus). The result will be a concordance.
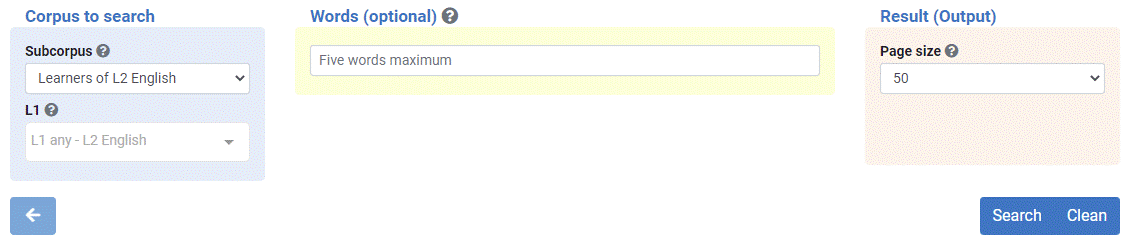
- In the blue area “Corpus to search” you can select the subcorpus to search (learners of L2 English or natives). You can also select the mother tongue (L1) of the learners.
- In the yellow area “Words (optional)”, you can type in the word(s) to search. Click on the question mark symbol for further details and examples. You can optionally leave this search box blank so as to browse (and download) the entire corpus.
- In the pink area “Result (Output)”, select the size of your output, i.e., how many concordance lines you want per page (50, 100, 500 or 1000).
ADVANCED SEARCH: Use this to look for words, grammatical categories, lemmas, frequencies, concordances, etc. You can apply several filters to restrict your search. You can also download the corpus texts here. We recommend you click on the question marks for additional help and examples.
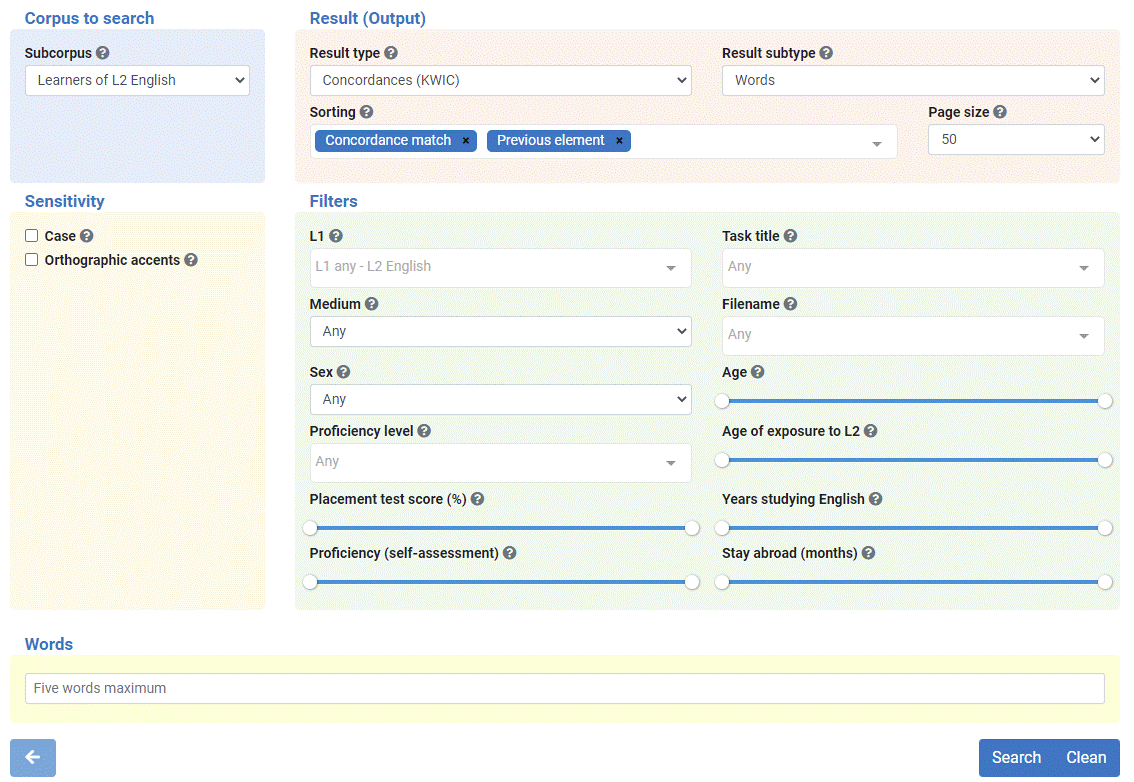
- In the blue area “Corpus to search”, you can select the subcorpus you are interested in (learners of L2 English or natives). You can also select the mother tongue (L1) of the learners.
- In the pink area “Result (Output)”, select the type of result type you need: concordances (KWIC), texts, simple frequency and full frequency. You can also select the result subtype (words, grammatical element, proximal words and proximal grammatical elements). You can sort your output by customising it. Finally, you can select the size of your output, i.e., the number of concordance lines per page (50, 100, 500 or 1000).
- In the pale yellow area “Sensitivity”, you can choose whether your search will be case and accent sensitive or not. Click on the question mark for additional help and examples.
- In the green area “Filters”, you can filter or narrow down your search according to a series of variables. Click on the question mark symbol for further details. For example, you can filter the output according to: the speakers’ mother tongue (L1), the medium (written or spoken), the learners’ proficiency level(s), their sex, their placement test score (in %), the proficiency score that they gave themselves (self-assessment), the title of the task or composition, the filename, the age of the speaker, the age at which the learnerers were first exposed to English, the years the learners have been learning English, and the months the learners have stayed in an English-speaking country.
-
In the yellow area at the bottom, you will see different options depending on the subresult type you have chosen:
-
WORDS: It searches for normal word(s) or combinations of words. For example: are, table, there is, I like, in spite of, … You can also use wildcards: * (asterisk for any number of characters), ? (for 1 character), (for either one word or the other). For example: - writ ⇒ concordances of words beginning with ‘writ’ and followed by any number of characters: *write, writer, writes, writing, written,** …
- *stand ⇒ concordances of words beginning with any number of characters and ending in ‘stand’: misunderstand, stand, understand, withstand.
- ?at ⇒ concordances of words beginning with a character and followed by ‘at’: hat, sat, cat, eat, fat, …
- da?e ⇒concordances of words starting with ‘da’ and ending with ‘e’ with one character in between: dame, dare, date, …
-
am are ⇒ concordances containing either ‘am’ or ‘are’.
-
GRAMMATICAL ELEMENTS: It can search for two types of elements:
- grammatical words or parts of speech (POS) like Noun, Adjective, Verb, Adverb, etc. You can subspecify the type of grammatical word (e.g., noun plural; verb past)
- lemmas provide all the word forms of a particular lemma (e.g., BE= am, are, is, was, were, be, being, been).
- WORDS PROXIM: It searches for a first word separated X words from a second word (example: “he 2 then” = he will then, he was then, he decides then,, …).
- GRAMMATICAL ELEMENTS PROXIM: It searches for a first grammatical word separated X words from a second grammatical word (example: “PRONOUN-PERSONAL 2 VERB-PARTICIPLE” = he was admitted, he has attempted, he has come, he is discovered, he had found, …; “PRONOUN-PERSONAL 3 VERB-PARTICIPLE” = he must have gotten, he has apparently collected, he was not allowed, I have recently watched, …).
-